
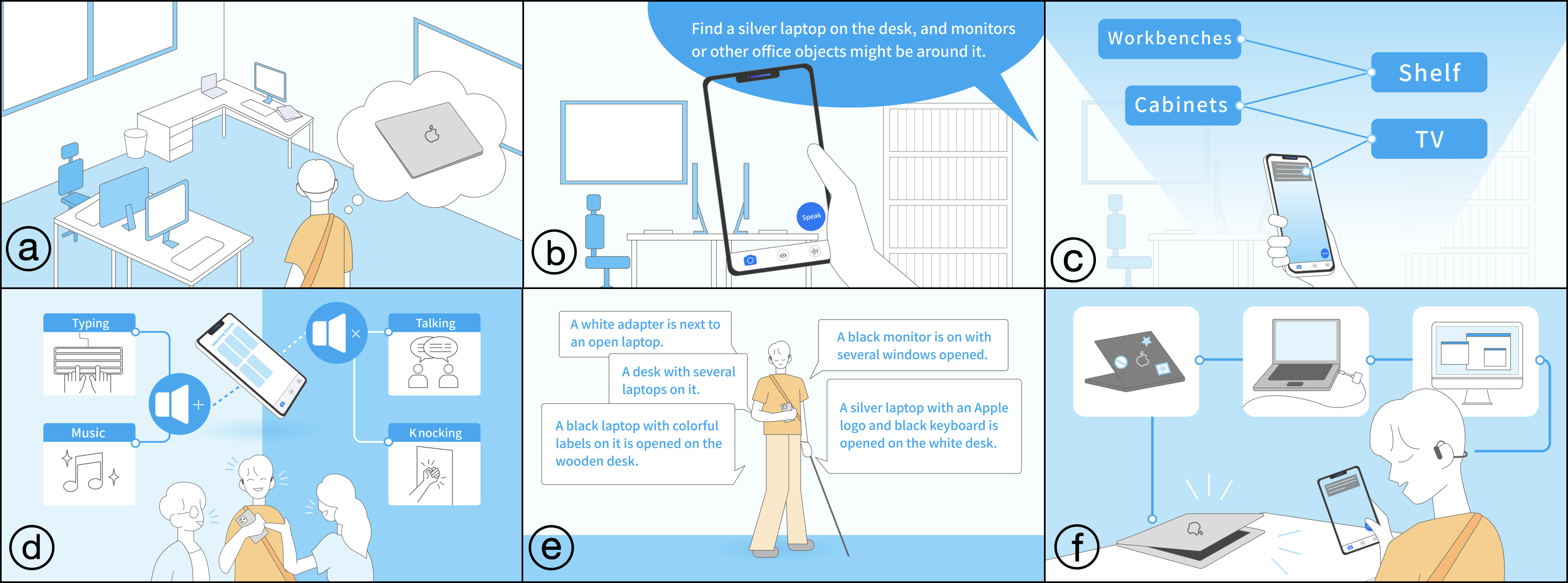
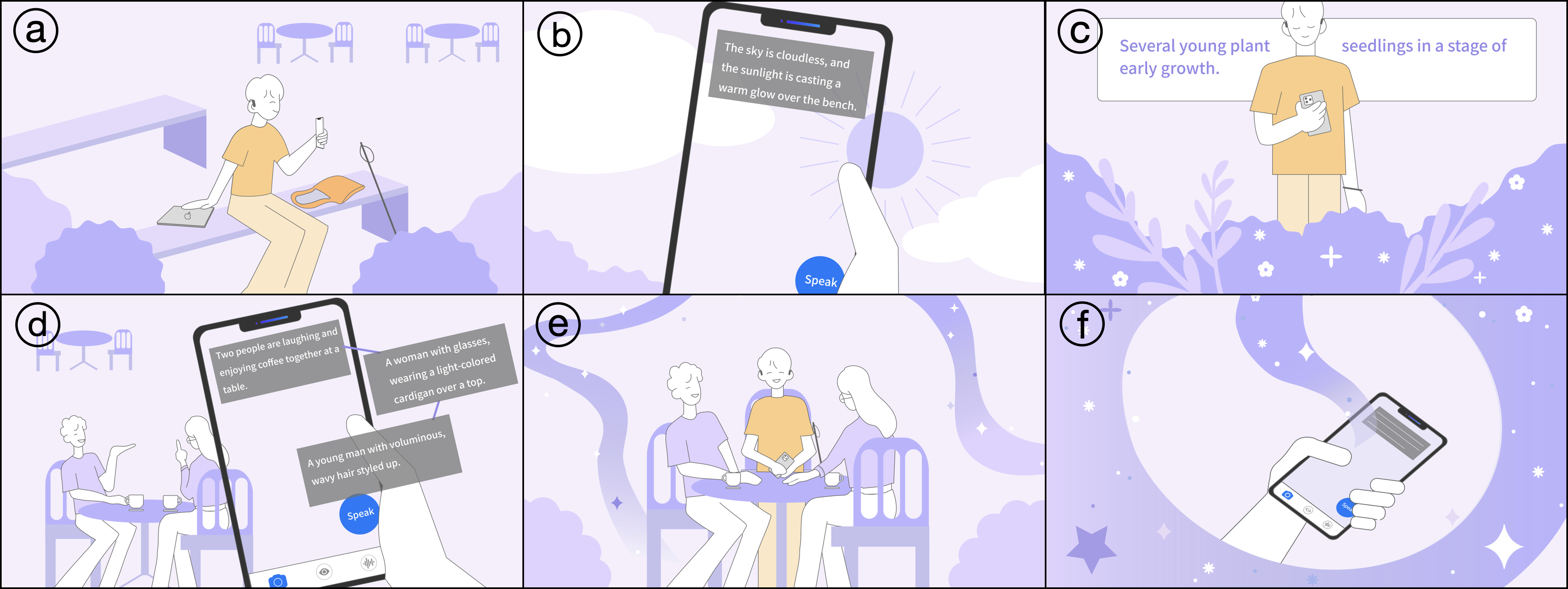
Automated live visual descriptions can aid blind people in understanding their surroundings with autonomy and independence. However, providing descriptions that are rich, contextual, and just-in-time has been a long-standing challenge in accessibility. In this work, we develop WorldScribe, a system that generates automated live real-world visual descriptions that are customizable and adaptive to users’ contexts. WorldScribe’s description is customized to users’ intent and prioritized based on semantic relevance. WorldScribe is also adaptive to visual contexts, e.g., providing consecutively succinct descriptions for dynamic scenes, while presenting longer and detailed ones for stable settings. Additionally, WorldScribe is adaptive to sound contexts, e.g., increasing volume or pausing in noisy environments. WorldScribe is powered by a suite of vision, language, and sound recognition models. It presents a description generation pipeline that balances the tradeoffs between their richness and latency to support real-time usage. The design of WorldScribe is informed by prior work on providing visual descriptions and a formative study with blind participants. Our user study and following pipeline evaluation show that WorldScribe can provide real-time and fairly accurate visual descriptions to facilitate environment understanding that is adaptive and customized to users’ contexts. Finally, we discuss the implications and further steps toward making live visual descriptions more context-aware and humanized.


@inproceedings{worldscribe,
author = {Chang, Ruei-Che and Liu, Yuxuan and Guo, Anhong},
title = {WorldScribe: Towards Context-Aware Live Visual Descriptions},
year = {2024},
isbn = {9798400706288},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3654777.3676375},
doi = {10.1145/3654777.3676375},
abstract = {Automated live visual descriptions can aid blind people in understanding their surroundings with autonomy and independence. However, providing descriptions that are rich, contextual, and just-in-time has been a long-standing challenge in accessibility. In this work, we develop WorldScribe, a system that generates automated live real-world visual descriptions that are customizable and adaptive to users’ contexts: (i) WorldScribe’s descriptions are tailored to users’ intents and prioritized based on semantic relevance. (ii) WorldScribe is adaptive to visual contexts, e.g., providing consecutively succinct descriptions for dynamic scenes, while presenting longer and detailed ones for stable settings. (iii) WorldScribe is adaptive to sound contexts, e.g., increasing volume in noisy environments, or pausing when conversations start. Powered by a suite of vision, language, and sound recognition models, WorldScribe introduces a description generation pipeline that balances the tradeoffs between their richness and latency to support real-time use. The design of WorldScribe is informed by prior work on providing visual descriptions and a formative study with blind participants. Our user study and subsequent pipeline evaluation show that WorldScribe can provide real-time and fairly accurate visual descriptions to facilitate environment understanding that is adaptive and customized to users’ contexts. Finally, we discuss the implications and further steps toward making live visual descriptions more context-aware and humanized.},
booktitle = {Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology},
articleno = {140},
numpages = {18},
keywords = {LLM, Visual descriptions, accessibility, assistive technology, blind, context-aware, customization, real world, sound, visually impaired},
location = {Pittsburgh, PA, USA},
series = {UIST '24}
}